
Over the past few years, I’ve encountered all sorts of confusion about how cloud resources should be architected, accessed, and consumed. In this post, which is the first in a series, I will walk through some networking basics relevant to cloud connectivity. The next post covers methods for connecting to cloud providers, and subsequent posts will dive deeper into specific topics.
Network Basics
The internet runs on – you guessed it – the Internet Protocol (IP), which is what you’ll use to connect to the various cloud providers. Overall, we’re running out of unallocated public IPv4 addresses, although that shortage doesn’t seem to apply to cloud providers just yet. IPv4 is well understood, and it is not going anywhere for many years, but now is the time to consider your IPv6 strategy. There is no reason to be afraid of IPv6, and it solves many of the workarounds put in place for IPv4 over the past decades, like Network Address Translation (NAT).
Overwhelmingly, the problem that comes up again and again when it comes to cloud connectivity, is basic routing and overlapping IP address spaces. With IPv4, this is a planning exercise that many people fail to do. With IPv6, this problem disappears, due to the massive number of unique addresses available. The crux of this issue is that every router that moves packets across a network can only have one entry in its routing table for each destination subnet. When all subnets are unique, this is easily accomplished, but almost every corporate network is using RFC 1918 private addresses somewhere. To put it simply, if you’re using 10.0.1.0/24 on your corporate network, you can’t use that specific range anywhere else. If you do, anything deployed in that duplicate network will not be able to communicate with the original range.
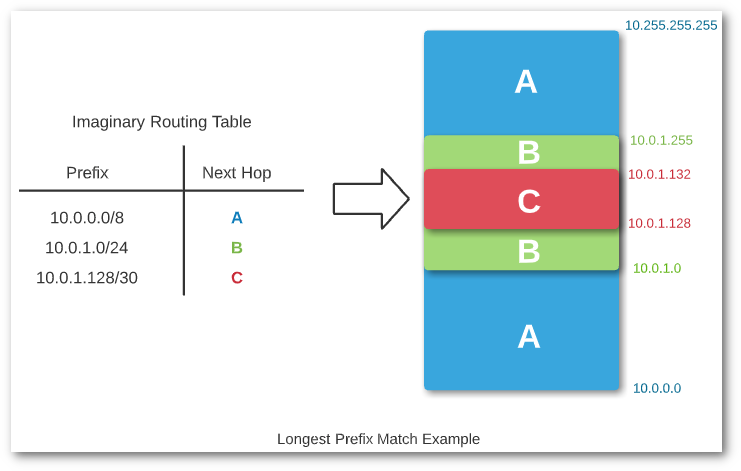
One trick commonly deployed to address overlapping network ranges is to use longest prefix match. Basically, this means that the route to the most specific network is the one that will be used. For example, if a router has valid routes for 10.0.0.0/8, 10.0.1.0/24, and 10.0.1.0/30, the last route is the most specific. This is easy to spot, as the subnet mask, /30, is a larger number than the other routes listed. Some newer network fabrics even create “host routes” - /32 in IPv4 or /128 in IPv6 – for every endpoint. Since these are the most specific routes possible, they always “win”, and they allow for great flexibility in terms of where endpoints are connected. In the world of networking, every decision like this involves a tradeoff. In this case, the tradeoff is flexibility versus a potentially large routing table. Luckily, we are in an era where network hardware is not as resource constrained as it was in decades past, so having hundreds of thousands of known routes is less of a risk. I’m placing a bet that we’ll see this approach used more and more. Regardless, this is a tool you can use when designing your network to make efficient use of your IP address ranges. If I’m able to get across one point through this post, it’s the important of planning ahead. Plan your IP addressing scheme, for both IPv4 and IPv6, since it’s inevitable that you will need to use both eventually.
One last point to mention is the importance of DNS. In a perfect world, no one would ever memorize an IP address (unless it’s for a DNS server, and 8.8.8.8 is mercifully easy to remember). Unfortunately, this is not the case. Hardcoding IP addresses is common practice, and I still run across people who don’t “trust” DNS or claim that some obscure application doesn’t support it. Name resolution and service discovery are incredibly important functions in the cloud, to the point that DNS has a 100% uptime SLA with some providers. In many cases, DNS is the only service that is guaranteed to be available all the time. If everything on your network is using DNS hostnames, and DNS is accurate and easy to update, changing the IP address of an endpoint becomes a much easier task. DNS has been around almost as long as the internet itself, so it’s high time that we do the heavy lifting to use DNS hostnames everywhere instead of IP addresses.
Security and Statefulness
I would be remiss to write about cloud connectivity without mentioning security. Figuring out how to allow legitimate traffic through firewalls and Access Control Lists (ACLs) is a joy that every network engineer gets to experience, and the sheer number of malicious actors means we all must keep security at top of mind when planning and operating our networks. Securing networks means adding complexity, and like an IP addressing scheme, needs careful planning.
While properly securing networks is critical, it’s important to understand exactly how it’s done, and what effect is has on our network. IP was designed with the end-to-end principle in mind. The original designers envisioned networks that purely moved packets, with any necessary intelligence implemented at the endpoints. A destination address would be all that is needed to get a packet where it needs to go. While that is not the reality of modern networking, it is still a worthy goal.
Network appliances, like firewalls, typically introduce some sort of state tracking. This is why some firewalls are referred to as “stateful firewalls” - they track the connection state of traffic flows as they traverse the firewall, and they use that state to determine whether to forward additional traffic. NAT Gateways and Load Balancers track state for similar reasons. As more state is stored on network appliances, we move further and further away from the ideal of the end-to-end principle. This isn’t necessarily a bad thing, but it is worth understanding, as well as architecting networks that minimize the reliance on state stored in appliances. I have seen massive web applications that are completely reliant on proprietary load balancer features. This is a situation that should be avoided. Just because you can use your network to solve a specific problem doesn’t mean that you should.
In terms of security policy, my best advice is to choose specific points for policy enforcement, and make sure they are well understood. In a typical enterprise network, this is usually obvious since policy enforcement happens at the firewall, although this has started to change with the advent of micro-segmentation. Cloud providers provide several options for applying security policy. Using AWS as an example, security policy can be applied at the instance (VM) level with security groups, or at the subnet level with network ACLs. Whichever method you choose, stay consistent, and document your security practices. A good rule of thumb is to apply security policy as close to the endpoint as possible.
Wrap Up
Certainly, there are many technical requirements to consider when it comes to connecting to the cloud. I hope you will consider the planning and design requirements first, to put yourself in a position for success. Networking basics, like IP schemes and routing, as well as a good understanding of network security, and how state affects your traffic flows are subjects every technical cloud consumer needs to understand.
Please leave a comment or reach out to me on Twitter and let me know if there is anything I’ve missed! My next post will cover the various methods available for connecting to the cloud.
Comments are powered by Disqus, which uses cookies.